Mio, tuo o nostro? Uno studio sulla condivisione dei dati scientifici in Genetica Umana - Materiali e Metodi - pag 4/10
Autori: Nicola Milia1,3, Alessandra Congiu1,3, Paolo Anagnostou1,2, Francesco Montinaro2, Marco Capocasa2, Emanuele Sanna3 e Giovanni Destro Bisol1,2*
Autori: Nicola Milia1,3, Alessandra Congiu1,3, Paolo Anagnostou1,2, Francesco Montinaro2, Marco Capocasa2, Emanuele Sanna3 e Giovanni Destro Bisol1,2*
1) Università di Roma ‘La Sapienza’, Dipartimento di Biologia Ambientale, Roma Italy (2)Istituto Italiano di Antropologia, Roma, Italy (3)Università di Cagliari, Dipartimento di Biologia Sperimentale, Cagliari, Italy *destrobisol AT uniroma1 dot it
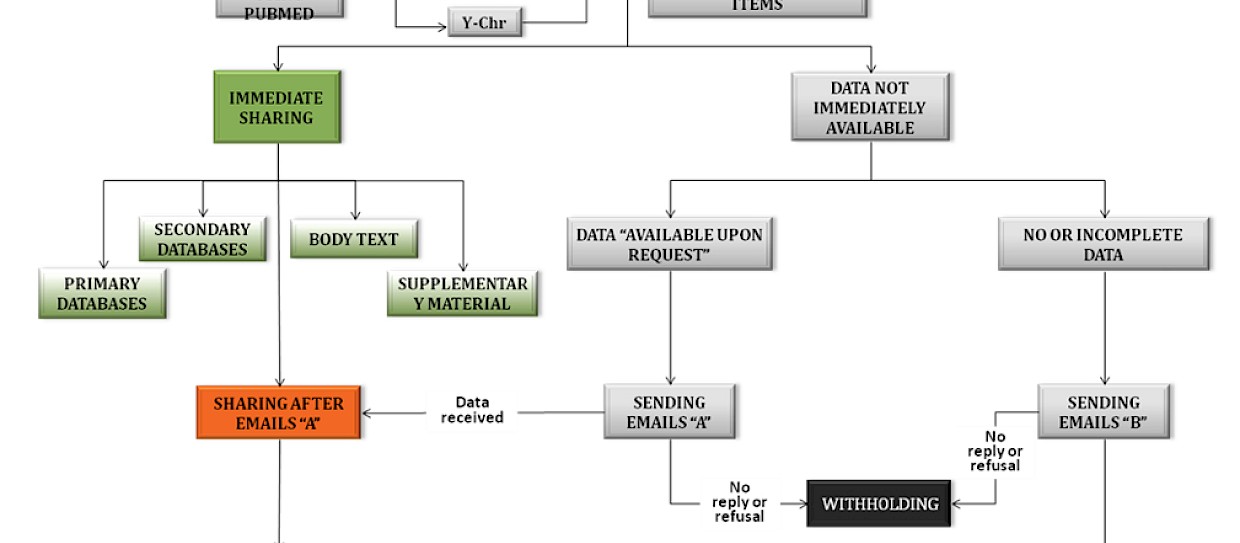
Il dataset iniziale comprendeva 1187 documenti indicizzati tra il 1 ° Gennaio 2008 e il 31 dicembre 2011 nella banca dati PubMed (http://www.ncbi.nlm.nih.gov/pubmed), selezionati utilizzando le parole chiave ''mitochondrial DNA and human population” e “Y chromosome and human population” (vedi figura 1).
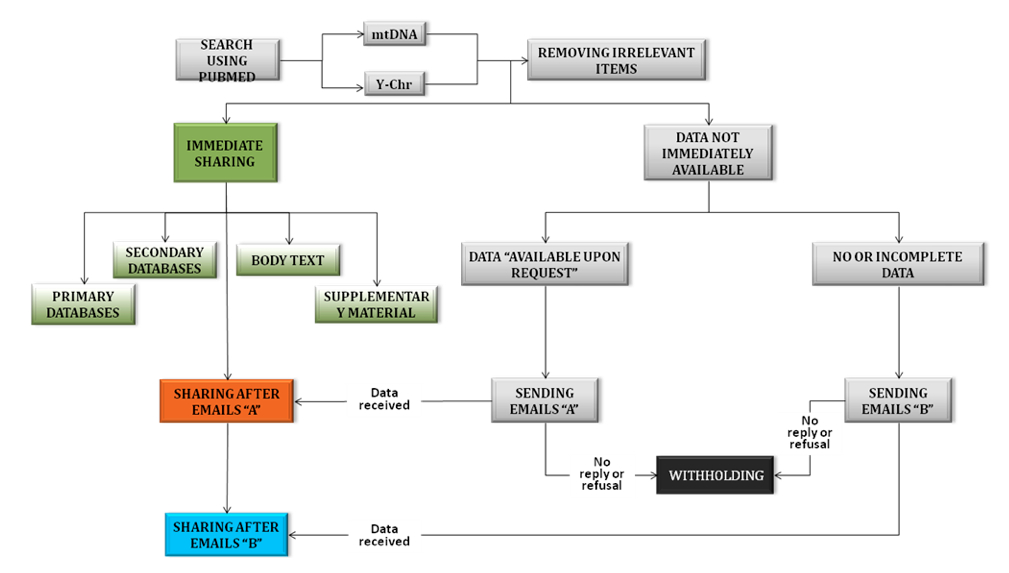 Figura 1 - Procedura utilizzata per analizzare le pubblicazioni riguardanti la variabilità nelle popolazioni umane di polimorfismi del Dna mitocondriale e del cromosoma Y.
Figura 1 - Procedura utilizzata per analizzare le pubblicazioni riguardanti la variabilità nelle popolazioni umane di polimorfismi del Dna mitocondriale e del cromosoma Y.
Sono stati analizzati un totale di 1187 lavori indicizzati su PubMed tra il 1 gennaio 2008 e il 31 dicembre 2011. Per la ricerca sono state utilizzate le parole chiave "mitochondrial DNA and human population" e "Y chromosome and human population", inoltre abbiamo impostato i seguenti limiti: "uomo" per le specie e "inglese" per la lingua.
Dopo aver rimosso gli studi non rilevanti (ad esempio studi non pertinenti alle popolazioni umane, recensioni o meta-analisi), per un totale di 253 sul DNA mitocondriale e 290 del cromosoma Y, il dataset finale è risultato essere composto da 508 lavori pubblicati in 101 riviste diverse (vedi tabella S1 e Tabella S2 del lavoro originale: http://www.plosone.org/article/info%3Adoi%2F10.1371%2Fjournal.pone.0037552).
L’analisi ha seguito la procedura descritta nella diagramma di flusso riportato in figura 1. Del dataset sono stati considerati come “condividenti” solo quei lavori i cui dati riportati permettessero un analisi e un riutilizzo senza alcuna forma di limitazione.
Invece, i lavori in cui non erano presenti i dati o riportati in modo parziale (ad esempio, solo una parte dei dati grezzi prodotti è risultata pienamente disponibile o erano presenti solo i dati derivati dalle analisi statistiche) sono stati inclusi nel categoria “dati trattenuti” (vedi tabella per maggiori informazioni sul tipo di dati classificati come trattenuti).
Abbiamo diviso il nostro dataset secondo la classificazione “condivisi” o “trattenuti” secondo le informazioni contenute nei lavori, cercando di recuperare i dati mancanti da banche dati online o repository solo quando erano esplicitamente indicati nel testo. Come complemento dell'esame dei lavori pubblicati (da cui abbiamo ottenuto l'immediata percentuale di “condivisione''), abbiamo chiesto ai corresponding authors dei lavori i cui dati sono risultati essere “trattenuti” se fosse possibile inviare le informazioni mancanti.
Ciò è stato fatto attraverso 3 richieste via e-mail nel corso di un periodo di tre settimane (Figura 2). Al fine di evitare qualsiasi influenza sulla risposta autore, non è stato fatto nessun accenno, nelle richieste, del nostro studio sulla condivisione dei dati (vedi testo S1).
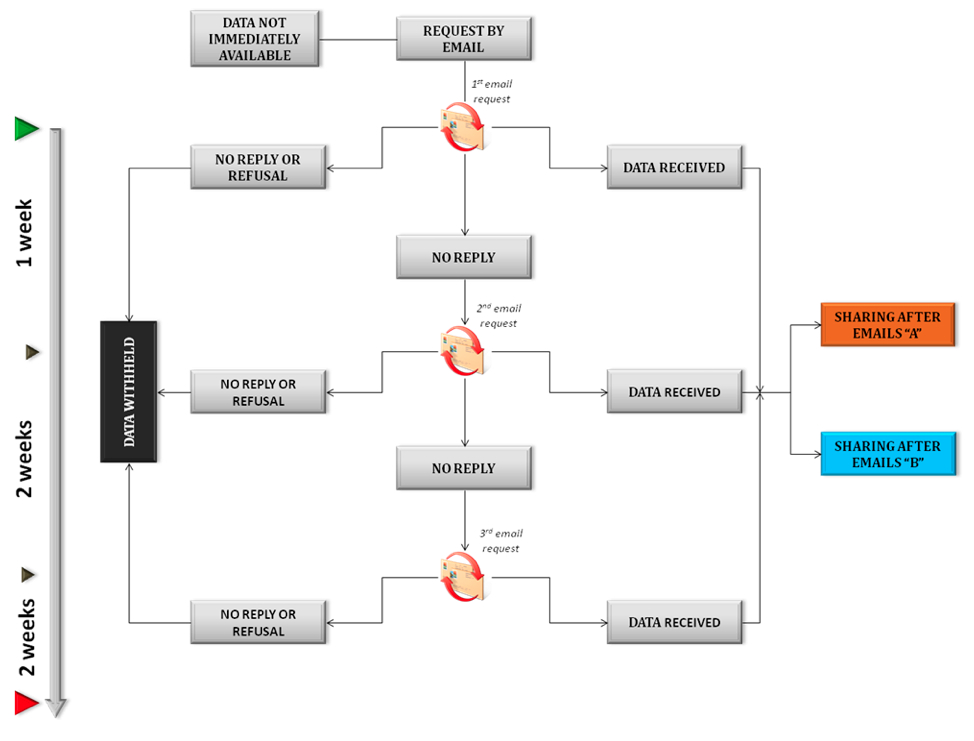
Figura 2 - Procedura utilizzata per richiedere i dataset non condivisi. Le prime due e-mail sono state inviate dal primo autore del presente lavoro (nicola.milia @ uniroma1.it), mentre la terza richiesta è stata inviata dall’autore senior (destrobisol @ uniroma1.it). La raccolta dei dati è stata chiusa cinque settimane dopo la prima richiesta.
I set di dati condivisi e trattenuti sono stati analizzati in relazione a: (I) campo di ricerca a cui lo studio può essere assegnato, (ii) il tipo di politica editoriale del journal della pubblicazione, (iii) impact factor del journal della pubblicazione, (iv) il numero di citazioni ricevute, (v) quantità approssimativa delle risorse utilizzate per generare i set di dati.
In tutte queste analisi, abbiamo considerato come condiviso sia i dati condivisi immediatamente sia quelli ottenuti dopo le richieste tramite e-mail inviate agli autori di articoli che dichiaravano la loro disponibilità ad inviare i dati dopo specifica richiesta.
Il dataset è stato suddiviso secondo il campo di appartenenza della pubblicazione (genetica evoluzionistica, medica e forense). Tutti e tre questi campi di ricerca non presentano differenze dal punto di visto dello studio genetico e genomico, ma possono essere distinti secondo i loro obiettivi finali.
In sostanza, abbiamo assegnato ai lavori (e alle serie di dati corrispondenti) inerenti la storia evolutiva dei gruppi umani, soprattutto in termini di demografia e adattamento, al campo della genetica evoluzionistica. I lavori riguardanti l'identificazione di individui o test di rapporti di parentela ai fini giuridici sono stati assegnati al campo delle scienze forensi.
Infine le pubblicazioni incentrate sulle cause e l'ereditarietà delle malattie genetiche, nonché la loro diagnosi e gestione, sono state attribuite al campo delle scienze mediche. Quando l'assegnazione di un lavoro risultava essere non possibile per via obiettivi di ricerca ambigui o non esplicitati, è stato utilizzato come criterio aggiuntivo la categoria ISI della rivista scientifica.
Il tipo di politica editoriale è stata valutata utilizzando le informazioni riportato nelle linee guida per gli autori di ogni giornale: “politica editoriale debole” sono quelle in cui gli autori sono invitati a condividere i dati, mentre “politiche editoriali forti”, quelle in cui la condivisione dei dati è indicata come obbligatoria (Vedi rif. 9 per un'analisi più dettagliata delle politiche di giornale).
Per ogni singola rivista è stato considerato l’impact factor riportato da ISI Reuters nel giugno 2009. Abbiamo anche determinato il numero di citazioni ricevute sia per i lavori “condividenti” sia per quelli in cui i dati risultano essere “trattenuti” ed inoltre abbiamo stimato la quota delle risorse utilizzate per generare i dati.
Il numero di citazioni è stato ottenuto utilizzando il database Scopus (http://www.scopus.com).
Allo scopo di rendere i dati confrontabili, ogni numero di citazioni ricevute è stato ponderato considerando il numero di mesi trascorsi dalla pubblicazione del lavoro. Lavori molto recenti (pubblicati negli ultimi sei mesi del 2011) e auto-citazioni sono stati escluse da questa analisi.
Per distinguere l'effetto di diverse variabili che potrebbero potenzialmente influenzare il numero di citazioni, è stata effettuata un analisi multivariata utilizzando un approccio di regressione lineare ponendo come covariate l’impact factor, il tempo trascorso dalla pubblicazione e il numero di autori.
Per ottenere una stima approssimativa delle risorse utilizzate per la produzione dei dati condivisi e trattenuti, abbiamo prima definito il parametro di costo unitario (CU) per ciascun tipo di polimorfismo del DNA mitocondriale e del cromosoma Y.
In sostanza, i valori adottati come CU si basano sul numero di sequenziamenti o genotipizzazioni che occorrono per generare i dati corrispondenti (Tabella S4 del lavoro originale).
Abbiamo preso in considerazione due diversi valori di CU per il sequenziamento completo del DNA mitocondriale, genotipizzazione di SNP (Single nucleotide polymorphisms) del mtDNA e SNP del cromosoma Y in quanto il loro costo può variare notevolmente a seconda del metodo utilizzato.
Il costo approssimativo per ciascun set di dati è stato ottenuto moltiplicando il costo unitario del polimorfismo analizzato per il numero di individui genotipizzati per ogni polimorfismo.
In questi calcoli, inoltre, abbiamo ipotizzato che la condivisione dei dati non implica alcuna costo aggiuntivo. Infatti, nelle più importanti banche dati online per mtDNA e per polimorfismi del cromosoma Y (ad esempio GenBank, YHRD e EMPOP, vedi sotto) è completamente gratuito.
Inoltre, solitamente non viene pagato nulla agli editori per complementare la pubblicazione di un eventuale materiale supplementare online. Un file (in formato Access, File S1) che rende possibile effettuare la riproduzione passo per passo del nostro protocollo viene fornito come materiale supplementare nel lavoro originale.
Indice articolo:
- Introduzione -pag 1/10
- La condivisione dei dati: pro e contro - pag 2/10
- La condivisione dei dati in Genetica Umana - pag 3/10
- Materiali e Metodi - pag 4/10
- Risultati e Discussione - pag 5/10
- Campi ricerca, impact factor - pag 6/10
- Alcune proposte pratiche - pag 7/10
- Bibliografia - pag 8/10
- Tabella 1 - pag 9/10
- Tabella 2 - pag 10/10