Mio, tuo o nostro? Uno studio sulla condivisione dei dati scientifici in Genetica Umana - Risultati e Discussione - pag 5/10
Autori: Nicola Milia1,3, Alessandra Congiu1,3, Paolo Anagnostou1,2, Francesco Montinaro2, Marco Capocasa2, Emanuele Sanna3 e Giovanni Destro...
Autori: Nicola Milia1,3, Alessandra Congiu1,3, Paolo Anagnostou1,2, Francesco Montinaro2, Marco Capocasa2, Emanuele Sanna3 e Giovanni Destro Bisol1,2*
1) Università di Roma ‘La Sapienza’, Dipartimento di Biologia Ambientale, Roma Italy (2)Istituto Italiano di Antropologia, Roma, Italy (3)Università di Cagliari, Dipartimento di Biologia Sperimentale, Cagliari, Italy *destrobisol AT uniroma1 dot it
In primo luogo, abbiamo selezionato il dataset da analizzare attraverso l’utilizzo di parole chiave in Pubmed (si veda [28] per un approccio simile), la più grande banca dati online di documenti di ricerca bio-medica, piuttosto che concentrarci su specifiche riviste [18], [29], [30].
In questo modo, abbiamo potuto valutare meglio il quadro generale relativo agli studi sulla variabilità genetica umana e in specifici settori di ricerca (scienze evoluzionistiche, scienze forensi e scienze mediche).
In secondo luogo, abbiamo cercato di fare un passo in più, superando la semplice distinzione tra dati condivisi o trattenuti, definendone dettagliatamente le varie modalità. Ciò ha reso possibile non solo valutare la facilità di accesso alle informazioni genetiche ma anche definire meglio quali siano le modalità che non permettono un’effettiva condivisione.
In terzo luogo, abbiamo completato l’analisi delle pubblicazioni attraverso delle richieste agli autori i cui set di dati sono risultati non condivisi al fine di ottenere una stima più realistica della reale disponibilità di dati scientifici.
La condivisione dei dati non è ancora una pratica comune negli studi sulla variabilità genetica umana.
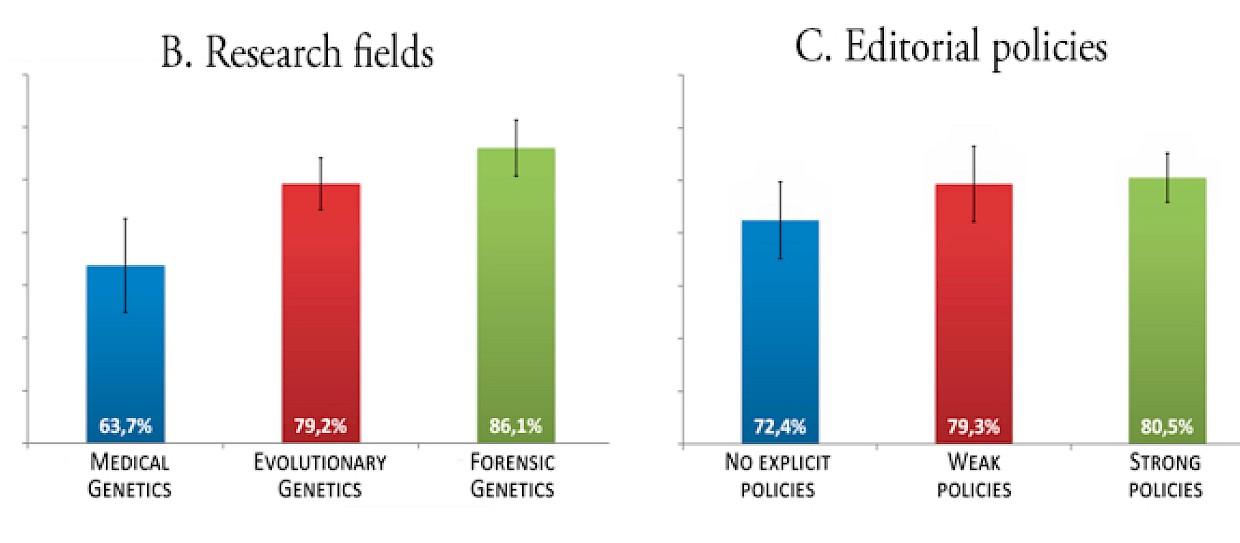
Come mostrato nella figura 3, una parte consistente dei dataset (23,2%) non è immediatamente condivisa attraverso il materiale pubblicato o tramite le informazioni in esso contenute (nel corpo del testo, materiale supplementare o banche dati on-line), mentre una frazione importante (16,6%) continua ad essere trattenuta nonostante le nostre richieste email.
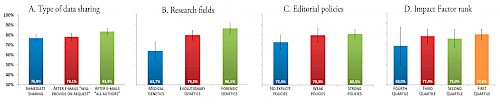
Figura 3 - Percentuali di condivisione di dati in pubblicazioni riguardanti la variabilità nelle popolazioni umane di polimorfismi del DNA mitocondriale e del cromosoma Y.
Le barre verticali indicano intervalli di confidenza al 95%. (A) Nella categoria "immediate sharing" (sharing immediato), abbiamo riportato la percentuale di dataset condivisi nel testo principale, nel materiale supplementare o banche dati on-line che sono stati esplicitamente indicati nel lavoro, le email "will provide on request" (fornirò i dati su richiesta) sono state inviate agli autori corrispondenti che esplicitamente dichiaravano nel lavoro la loro disponibilità all’invio dei dati; Le email "all authors" sono state inviate a tutti gli autori dei dataset “trattenuti”. I risultati riportati nelle caselle B, C e D sono stati ottenuti utilizzando le percentuali di condivisione ottenute dopo le risposte positive alle e-mail "will provide on request" . Abbiamo considerato come negative le risposte in cui gli autori hanno richiesto informazioni dettagliate circa l'uso dei dati e / o richieste di coauthorship prima dell’invio dei dati. (B) I dataset sono stati assegnati a ciascun settore di ricerca in relazione alle finalità di ricerca, come indicato nel lavoro. Quando l' assegnazione di un lavoro risultava essere non possibile per via obiettivi di ricerca ambigui o non esplicitati, è stato utilizzato come criterio aggiuntivo la categoria ISI della rivista scientifica. (C) Il tipo di politica editoriale è stata valutata utilizzando le informazioni riportato nelle linee guida per gli autori di ogni giornale: “politica editoriale debole” sono quelle in cui gli autori sono invitati a condividere i dati, mentre “politiche editoriali forti”, quelle in cui la condivisione dei dati è indicata come obbligatoria. (D), La classificazione è stata fatta in base ai valori del fattore di impatto ISI rilasciate da Reuters nel giugno 2009.
Non è stata osservata alcuna differenza significativa tra i polimorfismi del mtDNA e quelli del cromosoma Y (Tabella 1), ma l'uso frequente di GenBank per i dati del DNA mitocondriale (69 su 185 set di dati condivisi, corrispondente al 37,3%) li rende più facilmente accessibili (Tabella 2).
Tra i dati trattenuti, la parte più consistente (75 su 119 serie di dati, 63,0%) è data dal fatto che i dati sono presentati solo come derivanti dalle analisi statistiche, mentre meno frequentemente, i dati individuali sono presentati ma non sono disponibili in forma completa (10 su 119, 8,4%), o soltanto un sottocampione dei dati è effettivamente condiviso (34 su 119, 28,6%) (cfr. tabella S3 del lavoro originale per maggiori dettagli).
Solo in nove lavori si dichiara la disponibilità all’invio dei dati su richiesta, il che rende qualsiasi tipo di valutazione sulle percentuali di risposte positive alle richieste tramite e-mail poco attendibile. Tuttavia, bisogna notare che non tutti gli autori (7 su 9, 77,8%) in realtà hanno inviato i loro dati come promesso nella pubblicazione.
Come previsto, si è ottenuta una bassa percentuale di risposte positive da parte dei corresponding authors dei rimanenti dataset non condivisi (29 su 117, 24,8%), anche se la nostra percentuale di risposte positive ottenute (36 su 126, 28,6%) è superiore a quella registrata in uno studio precedente che ha analizzato i lavori pubblicati in PLoS Clinical Trials e PLoS Medicine (1 su 10, 10%) [18], e non si discosta di tanto da quanto osservato in riviste pubblicate dall'American Psychological Association (64 su 249, 25,7%) [30].
Indice articolo:
- Introduzione -pag 1/10
- La condivisione dei dati: pro e contro - pag 2/10
- La condivisione dei dati in Genetica Umana - pag 3/10
- Materiali e Metodi - pag 4/10
- Risultati e Discussione - pag 5/10
- Campi ricerca, impact factor - pag 6/10
- Alcune proposte pratiche - pag 7/10
- Bibliografia - pag 8/10
- Tabella 1 - pag 9/10
- Tabella 2 - pag 10/10